Wed, 31 Dec 2008
Parsec and Expression Parsing.
Haskell's Parsec parsing library (distributed with the GHC compiler since at least version 6.8.2) contains a very powerful expression parsing module Text.ParserCombinators.Parsec.Expr. This module makes it easy to correctly parse arithmetic expressions like the following according to the usual programming language precedence rules.
2 + a * 4 - b
Once parsed, the abstract syntax tree for that expression should look like this:
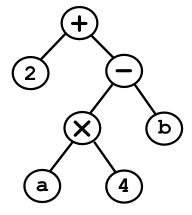
The original Parsec paper by Daan Leijen even gives a small example of using the expression parser. As can be seen below, the operators are defined in a table (ie a list of lists) where the outer list is a set precedence levels (from highest precedence to lowest) and each inner list specifies all the operators for that precedence level.
module Parser
where
import Text.ParserCombinators.Parsec
import Text.ParserCombinators.Parsec.Expr
expr :: Parser Integer
expr = buildExpressionParser table factor <?> "expression"
table :: [[ Operator Char st Integer ]]
table = [
[ op "*" (*) AssocLeft, op "/" div AssocLeft ],
[ op "+" (+) AssocLeft, op "-" (-) AssocLeft ]
]
where
op s f assoc = Infix (do { string s ; return f }) assoc
factor = do { char '(' ; x <- expr ; char ')' ; return x }
<|> number
<?> "simple expression"
number :: Parser Integer
number = do { ds <- many1 digit; return (read ds) } <?> "number"
The above simple example works fine but there is a potential for a rather subtle problem if the expression parser is used in conjunction with the Text.ParserCombinators.Parsec.Token module.
The problem arises when trying to parse expressions in C-like languages which have bitwise OR (|) as well as logical OR (||) and where the bitwise operation has higher precedence than the logical. The symptom was that code containing the logical OR would fail because the expression parser was finding two bitwise ORs. After banging my head against this problem for a considerable time, I posted a problem description with a request for clues to the Haskell Cafe mailing list with the following code snippet:
import qualified Text.ParserCombinators.Parsec.Expr as E
opTable :: [[ E.Operator Char st Expression ]]
opTable = [
-- Operators listed from highest precedence to lowest precedence.
{- snip, snip -}
[ binaryOp "&" BinOpBinAnd E.AssocLeft ],
[ binaryOp "^" BinOpBinXor E.AssocLeft ],
[ binaryOp "|" BinOpBinOr E.AssocLeft ],
[ binaryOp "&&" BinOpLogAnd E.AssocLeft ],
[ binaryOp "||" BinOpLogOr E.AssocLeft ]
]
binaryOp :: String -> (SourcePos -> a -> a -> a)
-> E.Assoc -> E.Operator Char st a
binaryOp name con assoc =
E.Infix (reservedOp name >>
getPosition >>=
return . con) assoc
Unfortunately, no real answer was forthcoming and while I still held out hope that an answer might eventuate, I continued to work on the problem.
Eventually, after reasoning about the problem and looking at the source code to the Token module I realised that the problem was with the behaviour of the reservedOp combinator. This combinator was simply matching the given string at the first precedence level it found so that even if the code contained a logical OR (||) the higher precedence bitwise OR would match leaving the second vertical bar character un-parsed.
My first attempt at a solution to this problem was to define my own combinator reservedOpNf using Parsec's notFollowedBy combinator and use that in place of the problematic reservedOp.
opChar :: String opChar = "+-/%*=!<>|&^~" reservedOpNf :: String -> CharParser st () reservedOpNf name = try (reservedOp name >> notFollowedBy (oneOf opChar))
This solved the immediate problem of distinguishing between bitwise and logical OR, but I soon ran into another problem parsing expressions like this:
if (whatever == -1)
.....
which were failing at the unary minus.
A bit of experimenting suggested that again, the problem was with the behaviour of the reservedOp combinator. In this case it seemed the combinator was matching the given string, consuming any trailing whitespace and then the notFollowedBy was failing on the unary minus.
Once the problem was understood, the solution was easy, replace the reservedOp combinator with the string combinator (which matches the string exactly and doesn't consume trailing whitespace), followed by the notFollowedBy and then finally use the whiteSpace combinator to chew up trailing white space.
reservedOpNf :: String -> CharParser st ()
reservedOpNf name =
try (string name >> notFollowedBy (oneOf opChar) >> whiteSpace)
Despite minor problems like the one above, I am still incredibly impressed with the ease of use and power of Parsec. Over the years I have written numerous parsers, in multiple host languages, using a number of parser generators and I have never before used anything that comes close to matching Haskell and Parsec.
Posted at: 07:28 | Category: CodeHacking/Haskell | Permalink

![[operator<< is not my friend]](http://yosefk.com/c++fqa/images/operator.png)
